
powered by Communication, Media, Sound and Interaction Design
As we now have some questions about what we want to find in the signal we can look for algorithms that can provide information on that. here the questions are listed again:
For the last question, we did not find an answer yet but we found an algorithm that would interest me personally to experiment with. the MFCC.
Or tonal coefficient is also known as Wiener entropy is a spectral measure that constitutes how ton-like or noise-like a sound is. By analyzing the ramps in the spectrum and determining their steepness it gives out a number between 0 and minus infinity where 0 is a few sine waves and -inf. pure noise. It can also be applied on subbands rather than across the whole band.
With the output of one number, the application of this could be quite straightforward. The distinction between the tonal and non-tonal content of a musician’s tonal repertoire gives great insight into the performative intent of that musician.
Spectral Entropy, with a choice of a number of sub-bands. If one band, a measure of general peakiness of the spectral distribution.
This calculates the distribution of the spectral energy in a frequency spectrum and outputs the frequency value which corresponds to the desired percentile. This means it puts out the frequency where the spectral roll-off is happening, which gives information of the cutoff frequency of a filter.
This measures the spectral centroid, which is the weighted mean frequency, or the “center of mass” of the spectrum. This means it can determine if the measured signal leans more on the bright or dull side.
Are „a small set of features of a signal (usually about 10-20) which concisely describe the overall shape of a spectral envelope. In MIR, it is often used to describe timbre.“ (https://musicinformationretrieval.com/mfcc.html) Because of the multitude of values, it is problematic to implement it as modulation source in a eurorack environment as it is. But with more understanding of the output, a conclusion might be drawn to either one or multiple control voltages drawn from it.
One property that puts our planned module apart from modules on the market which as we will get pitch-, gate-, and envelope-information from an input signal, is the usage of Music Information Retrieval (MIR). This relatively young and growing but still young field of research seeks to make music machine-readable with techniques of machine-learning. In todays’ music distribution which is by a big part catered to via streaming services, quick implementation and organization are crucial to monetize media collections and keep up with the market. This rather economic approach to music is merely one benefit to the capabilities of MIR. Things like source separation to create stems, for instance, transcription for notation programs, pitch tracking, tempo estimation and beat tracking for converting audio to MIDI for instance or have the chords of a song detected while playing it or Autotune, or key detection to quickly program quantizers in electronic music devices, can be useful tools in music education and music production and show a useful way to use MIR in an artistic sense.
There are more than methods to retrieve musical information. Some work with Data Source which derives its data mostly from digital audio formats such as .wav, .mp3, .ogg. Though many of those formats are lossy and machine listening is more deceptible to artifacts than the human ear much research in the field involves these in their data. Additionally, more and more metadata is mined from the web and incorporated into MIR for a better understanding of music in its cultural context.
Statistics and Machine learning play also an important role in this field of research. Many of the methods are comparing music to databases and come through that to information about music in question.
For the performance character of our module information retrieval has to come almost immediately from the signal put into the module without taking the computational time of searching databases. Feature representation must be the method in question to gain information quickly through an FFT for instance. Analysis of the music is achieved by summarising which is done by feature extraction. This summary has to give a feature representation that is reduced enough to reach a manageable set of values within a reasonable time frame.
As we ponder over the possibilities of MIR we should ask ourselves what could we retrieve from the signal to gain some knowledge over the expression of the musician playing into the synth. I did a short brainstorming with Prof. Ciciliani and we came up with a few parameters which we decided to make sense in a live performance.
This would give information about the sound coming from the instrument and if there would be a pitch to extract.
Information about the playing technique and depending on the instrument a form of expression as many instruments emit additional harmonics in the upper registers when played more vigorously.
This can be interpreted in more ways. Over a longer period to get additional modulation after a phrase to create some kind of call and response or a performance reverb if we want to think out of the box. Or in addition to the envelope follower compare the Atack ramps of the signal to create a kind of punch trigger when the playing gets more intense.
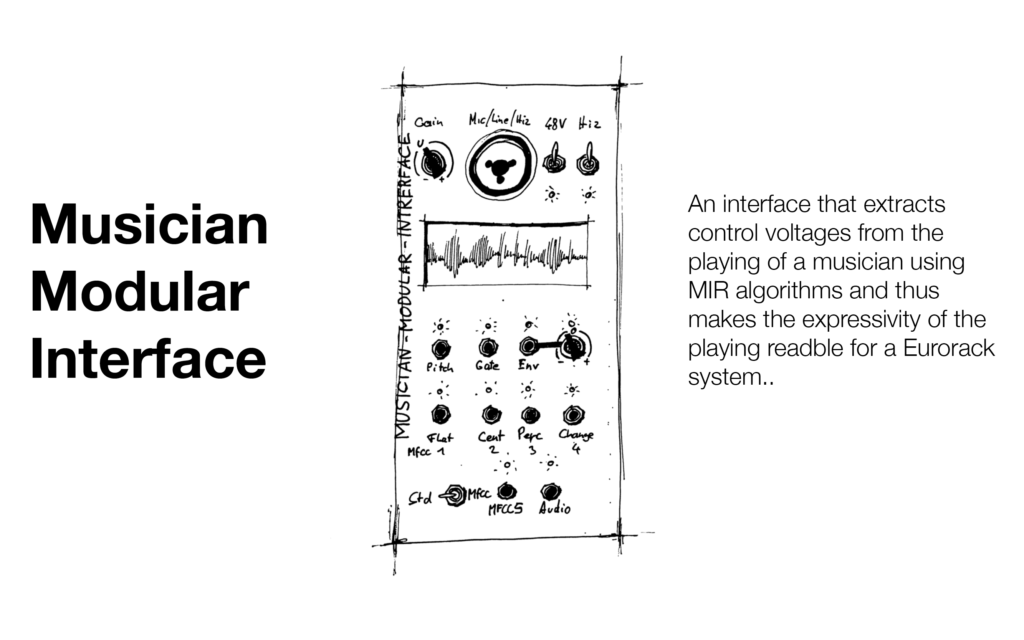
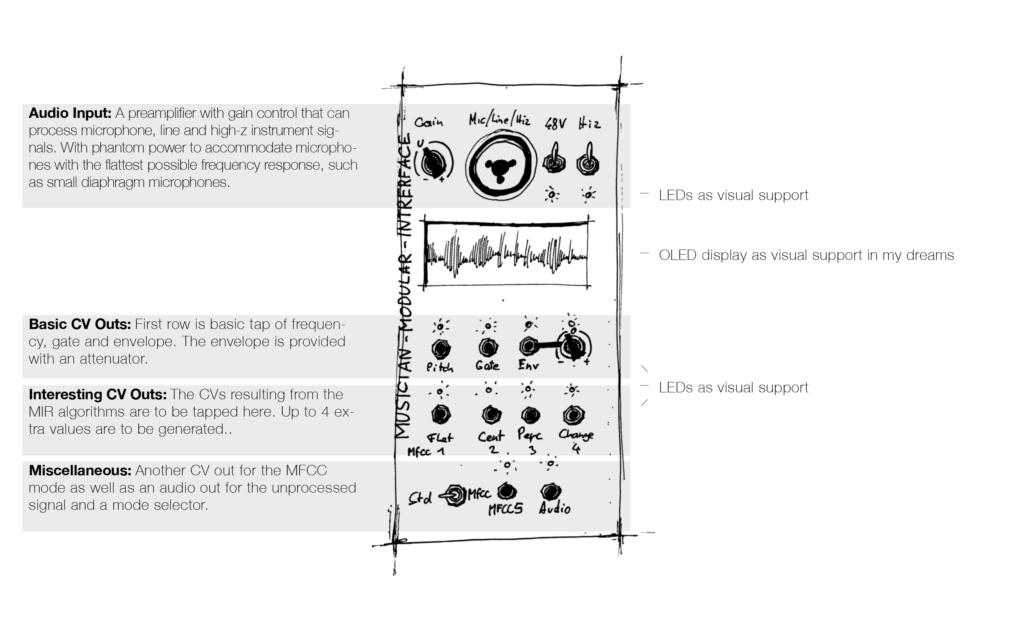
The Bela Starter Kit comes with a Beaglebone and the extension of the Bela Cape which houses a myriad of IOs. This kit will connect to Bela Pepper which is a PCB with a matching Faceplate for integrating the Beaglebone into a modular system. The assembly of the PCB is described on Bela.io with an illustrated manual and a bill of materials to get for building the DIY kit. This will be my task on my days off in February.

Pepper will be an 18 HP Module that provides Stereo IO, 8CV IO, 8 CV offset potentiometers, 4 buttons, and 10 LEDs for the Beaglebone to connect to my modular. There is also a Faceplate for a USB breakout included.

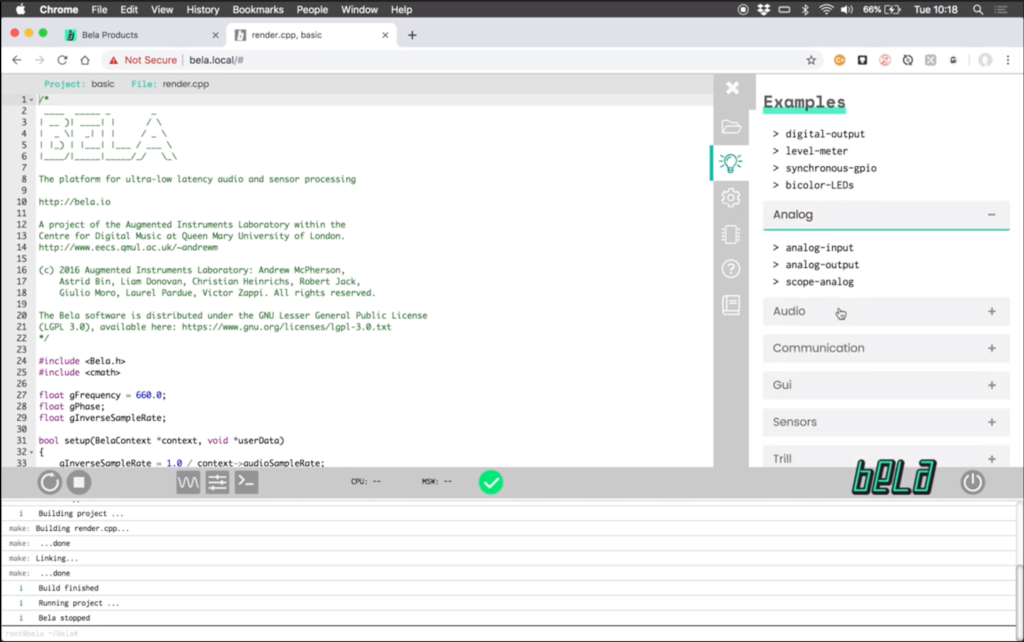
To implement my code into the Beaglebone, on the different Belaboards is a Browser-based Integrated Development Environment (IDE). An IDE is a set of tools for a programmer to develop, test, and debug software. In the Bela IDE, one can program in C++, Pure Data, Supercollider, or Csound. It contains example code to work with and learn basic skills to use the Bela hardware. There is sample code in every language the Beaglebone can work with. Additionally, there is also a Pin Diagram which identifies all the pins that can be found on the respective board that one uses. In my case as said before it will be the Beaglebone. Further, there is a library of pre-coded functions in there which can be used.
So there is a multitude of values to be extracted to pick up a musician’s expression in performance. If the music is written down, some of it is readable by the sheet music. Some of it however is an individual expression of the musician. which is far more abstract in character and much more difficult to pick up because it is not possible to predefine it or calculate it. So we have to quantize expression somehow directly from the performance. Clemens Wöllner suggests in his opinion article to quantify artistic expression with averaging procedures.
A big point of the expression is to raise the attractiveness of the musical piece one is playing to a point to make it one’s own in the sense of the performance. Individuality is highly valued in the expression of a performer. Cognitive psychology studies teach us that average modalities in visual and auditory modalities are viewed as more attractive. Averaging procedures typically produce very smooth displays in pictures and sound. Listeners of performance typically expect more from a concert or a recording than an even performance. As said individuality is highly appreciated in music.
In classical genres, expression is often added by subtle timing perturbations and fluctuations in dynamic intensity, as unexpected delays or changes in intensity that are different from the typical expectations of the listener can cause surprise and other emotional reactions and thus help the individual performer’s musical expression. In earlier decades of the 20th century, for instance, musicians typically employed large rubati which are deviations in note length, most of the melody voice. It is not as common anymore, the changes of note length are far smaller today. Research along these lines has for a long time studied expressive timing deviations from a non-expressive metronomic version. These timing deviations constitute an individual expressive microstructure. As performers are not able to render a perfect mechanical, metronomically exact performance. To quantify those timing variations using a so-called deadpan rendition as average, can not be a valid indicator of individuality.
So musical performances can be averaged according to the main quantifiable dimensions of duration, dynamic intensity, and pitch. As for the average performance, it was suggested in seminal studies 1997 by Repp that the attractiveness is raised by not deviating from the average, expected performance, but it is also considered a dull performance if there is no individuality in it by straying from the average.
Averaged deviations from the notated pitch in equidistant temperament could be analyzed. The sharpening or flattening of tones may reveal certain expressive intentions of individual performers. Also, musicians are able to shape the timbre of certain instruments to some extent which adds to their expression.
(see.: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3685802/#!po=71.7391 30.12.2021, 20:12.)
Since my work will be implemented in a eurorack system I attempted to find references of existing modules that would do a similar thing. As expected I found no modules where Music-Information-Retrieval is implemented. But there are Modules with which like Pichfollowers, envelope-followers, combinations of those two and separate building blocks.
The A-196 PLL is a Phase-locked-loop (PLL) module. PLL-circuits are commonly used in pitch-tracker devices. It is a comparative circuit that compares two oscillating signals in their relative Phase. The A-196 is more of a weird oscillator than a Modulation source but it has 3 different parts one of which is a PLL circuit.

Doepfer A-134-4C, Gap Synthesizer – Envelope Follower, Buchla – 230e Triple Envelope Tracker
These are quite ‚simple‘ envelope followers which take the amplitude of a signal over time and translate it into an envelope. Every module is its own interpretation of controllable parameters like threshold, attack, release or internal triggers (Buchla). As you might recognize the 230e is not a eurorack format, but as there are not many examples I included a Buchla module.



Also an envelope follower but with a twist. It has more functions one of which is an envelope follower but also a comparator module between two signals.

Here the envelope follower is combined with a pitch tracker and a trigger which are the basic values to play a synthesizer voice be it percussive or tonal. It also is equipped with its own set of adjustable parameters to control the inputs and outputs of the signal.

The Disting Mark 4 is a Digital signal processor which provides many algorithms for modular synthesis. One of those algorithms is a pitch and envelope tracker.

Is not an existing module. it is a concept in unclear development stage. The functions it may provide are the following:

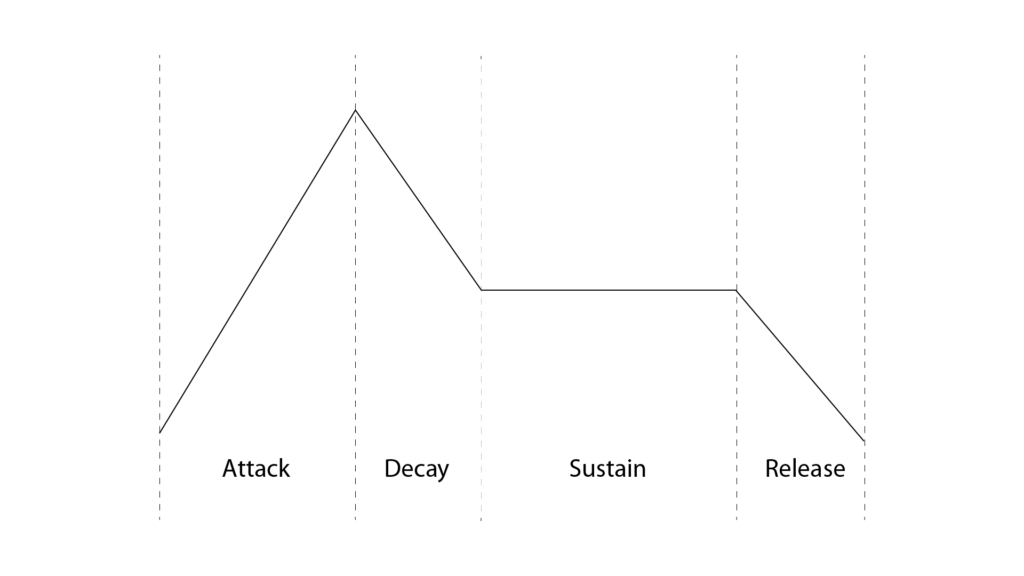
For the Musician–Synthesizer Interface it is important to translate the pitch, Amplitude-envelope and note length. But those are the Basic values that define the most basic values of translating Music into the air. The pitch and the relative length are defined for example by sheet music and the envelope by the Characteristics of the instrument played. The most common envelope found in synthesizers ist the ADSR shape standing for ‚attack‘, duration of the rising ramp of the signal, ‚decay‘, duration of falling ramp of the signal starting after the attack ramp is at its peak value, ‚sustain‘, value of the held signal as long as the gate is open and ‚release‘ duration of the signal falling from the last value to zero after the gate is closed. This is also one of the simplest ways to portray many acoustical instruments in their Amplitude envelopes.
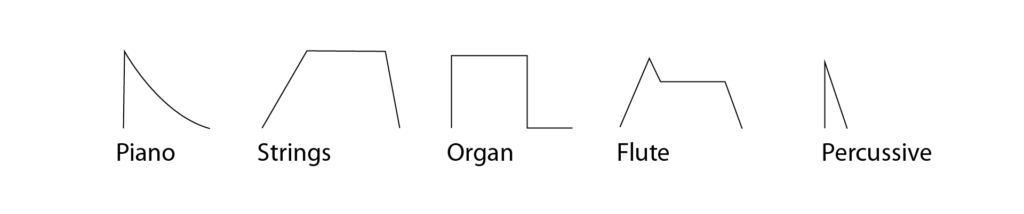
But the timbral structure of sounds are mostly not only described by their amplitude envelopes. Many musical instruments are defined by variations in pitch, and the color of the sound. So the simple amplitude picked-up by an envelope follower is a very basic tool to define the sound of a musician. Furthermore it only draws conclusions of the basic values a musician puts into his instrument. So to capture a musician more fully her expression plays a big role in the interpretation of control voltages.
So how can we define musical expression? As said before in most notation of western music pitch and relative length are written down, things like tempo and dynamics or direction for technique are written down in words or abbreviations. But the finer points of a performance which are mostly inherent to every musicians individuality are much nowhere to be found except the playing of the musician. So the common expression for tempo in italian are widely known as follows roughly from slow to fast: adagissimo, adagio, lento, andante, andantino, allegretto, allegro, presto, prestissimo. (Britanica)
As for dynamics roughly from quiet to loud: piano, pianissimo, mezzo piano, forte, mezzo forte, fortissimo and some changes in dynamics: fortepiano (loud then soft) sforzando (sudden accent) crescendo (gradually louder), diminuendo (gradually softer).
So those are nowadays all the definitions which a composer uses to translate his musical thoughts to the performer. but it wasn’t always like this.
„…[I]n much 17th- and 18th-century music, the composer notated only the main structural notes of the solo part, leaving the performer to improvise ornamental figuration.“
https://www.britannica.com/art/musical-expression
Those figurations or ornamentations gave the musician the freedom to express themselves and influence the tradition of the then current music.

Here you can see the bottom two lines are the composers’ structure of the piece and the top line are the individual ornaments an artist put over the piece.

In modern Midi keyboards, there are several possibilities to record expressions. The widest spread feature is the velocity control. This parameter is controlled by the velocity one hits the keys and thus can be easily added by keyboard performers in their playing like they would playing an acoustic instrument. With the synthesizer and the possibility to create the sound of the instrument individual to the performance also came the possibility to control parameters of a sound which in acoustic or electro-acoustic keyboard instruments with keys and pedals only really possible. The Pitch and Mod wheel were introduced to make such changes possible. The first was a spring-actuated week or stick which was mostly used to modulate the pitch like with a guitar. The other was an adjustable heel with which one could send fixed values or modulate them manually. The fourth modulation source developed for keyboard synthesizers is aftertouch. As the name suggests, it is applied by altering the pressure after the key is depressed. This can be applied mono- or polyphonically. All of those controls added to the expressivity of synthesizer performances mostly. Only one of those controls is determined before the tone or as the tone is generated. The others are applied in the decay of the sound. So those are 4 control values that have been proven to add expressivity in performance.
Ofcourse, these weren’t the only tools that were developed to do very expressive performances, although they are the most common ones. There is a multitude of midi controllers to add expression to an electronic music performance. The expressive E ‘Touché’ or ‘Osmose’, Buchla and Serge capacitive keyboards and joystick-controllers on synths like the EMS Synthy, Korg devices like the Sigma or the Delta and as controller module for Eurorack-, 5U-, Buchla- and Serge-modules.
Then there are control surfaces that take another approach to the whole concept of the Keyboard entirely. These Concepts go often but not always hand in hand with a synthesizer engine.
The Haken Continuum for instance is a Synthesizer with a control surface that can detect movement in 3 axes.
The Haken Continuum Fingerboard is an instrument born to be as expressive and as rewarding to play as an acoustic instrument. The uniquely designed sensitive playing surface has been symbiotically merged with its powerful synthesis sound engine to produce a truly unique playing experience. The Continuum is a holistic electronic instrument that puts its player at the heart of a uniquely fluent, gestural and intuitive musical playing experience.
https://www.hakenaudio.com/

The Roli SEA Technology which is implemented in rolis seaboard controllers is as roli puts it:
“Sensory, Elastic and Adaptive. Highly precise, information-rich, and pressure-sensitive. It enables seamless transitions between discrete and continuous input, and captures three-dimensional gestures while simultaneously providing the user with tactile feedback.”
www.roli.com

The Linnstrument is a control surface developed by famous instrument designer Roger Linn. Interesting here is the approach to not apply a piano-style keyboard but rather use a grid-style keyboard which rather reminds of the tonal layout of string and guitar instruments. With the linnstrument there is also a release velocity recorded which places it even more into guitar territories where pull-offs, when one rapidly pulls of the finger of a string to excite it and thus making it sound, is a standard technique.

So few of the looked at control surfaces if any have more than 4 modulatable values. This would be then a minimum for a module that should be able to translate the expression of an instrumentalist into control voltages.

Sarah Belle Reid is a Trumpet player and Synthesist who takes the sound of her brass instruments and puts them through her modules Systems like Buchla, Serge, or Eurorack. She has developed a device with which she translates her trumpet playing to CV and/or MIDI messages called MIGSI.
They Developed MIGSI in a big part to enable her to use all of the techniques Sarah Belle Reid has developed on her Instrument to translate into more than ‘just’ her instrument and open the horizon of the instrument the electronic music-making possibilities.
MIGSI: Minimal invasive gesture sensing interface. She calls it ‘electronically augmented trumpet’ too. The device was co-developed by her and Ryan Gaston around 2014. They also founded ‘Gradient’ a joint venture between them where they develop “handmade sound objects that combine elements of the natural world with electronic augmentation.” (vgl.: Gradientinstruments.com).
Migsi is a Sensor-based Interface with 3 types of sensors and 8 streams of Data. Pressure sensors around the valves which read the pressure of the grip force, an accelerometer that senses movement of the Trumpet, and optical sensors which reads the movement of the Valves.
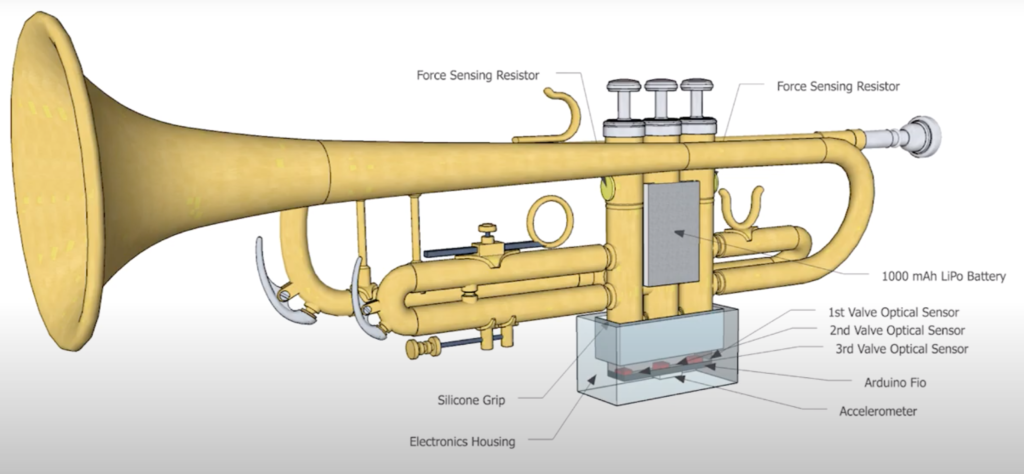
The hardware is then read by a MIGSI app which is a MAX map Patch. The app is used to process thee the audio signal of the trumpet, modulate external equipment with the sensor input or modulate a synth engine inside the MIGSI App.
(vgl.: https://www.youtube.com/watch?v=tbXgUDQaNv0)

While presenting my Ideas and reasoning how and why I choose the order of interest in them, I could give a clear statement of intention that programming and electronics should be a vital part of the final product.
From the Faculty of KUG Prof. Marco Ciciliani has chosen to work with me on my project. The Projekt – ‘Kidnapping the Sound of an Instrumentalist’ was my least favorite, but only because I would have done it outside of Uni anyway. His reasoning for choosing me was that he works with modular synthesis too.
‘Kidnapping the Sound of an Instrumentalist’
The main focus should be that the forthcoming device should be very performable. This means that I have to find a working surface which for one is familiar to me and secondly gives me enough room to develop in multiple directions. The performance aspect means that the Instrumentalist has to be able to convey their expression to the device and I have to be able to pick it up and use it for further modulation of my setup. Below is a chain of thoughts which stood at the very beginning of the project which concludes in a module for a modular Synthesizer.
The Idea of developing a Musician Interface Module was well received by Prof. Ciciliani with the remark that for the technical side I have to be self-sufficient for the largest part.
EXPRESSION OF A MUSICIAN LIES VERY MUCH IN THE SONIC COLORATION OF THE SOUND – FFT ANALYSIS
COULD WELL BE THE TOOL TO EXTRACT PARAMETERS FOR THE SONIC COLOR OF A SOUND – BREATH
CONTROLLERS RECORD EXPRESSION PARAMETERS TOO – COULD GRANULAR SYNTHESIS BE A GOOD WAY TO
CAPTURE SONIC COLOR OF A SOUND – IS GRANULAR SYNTHESIS ONLY A EFFECT OR DOES IT MAKE THE
SOUND ITS OWN – HOW MANY PARAMETERS DOES EXPRESSION HAVE – IS THERE EVEN A NUMBER – ARE
THERE DIFFERENCES BETWEEN INSTRUMENTS – ARE THERE ANY SIMILARITIES –
A MODULE: THE MUSICIAN INTERFACE
For the Analysis of the instrument, Music Information Retrieval (MIR) was suggested. Music information retrieval (MIR) is the interdisciplinary science of retrieving information from music. MIR is a small but growing field of research with many real-world applications. Those involved in MIR may have a background in musicology, psychoacoustics, psychology, academic music study, signal processing, informatics, machine learning, optical music recognition, computational intelligence, or some combination of these.
Machine analysis and human hearing often correlate unexpectedly. High frequencies for example have a lower audible harmonic spectrum than Lower frequencies but are received vastly differently by the human ear in terms of expression or sonic coloration. So there are many Experiments to attempt to find the right algorithm and workflow to translate expression by the musician.
MIR is inherently digital so the module will probably be driven by some kind of DSP. So the question is if there is a programable DSP chip with the right periphery to build a module around? Like a DSP raspberry Pi. Bela board, Arduino, Daisy, Teensy,…