Wavetable Synthesizer wurden erstmals in den 1970 von Firmen wie PPG oder Waldorf (Microwave) gebaut. Bands wie Depeche Mode sind bekannt für ihren Sound, der oftmals durch WTS zustande kam. Heutzutage findet man Wavetable Synthesizer hauptsächlich in digitaler Form, nicht zuletzt auch aufgrund der technischen Möglichkeiten. Einer der wohl bekanntesten davon ist wohl “Serum” von Xfer Records, oder “Massive” von Native Instruments.
Ein Unterschied zu anderen Syntheseformen sind die Oszillatoren. Während diese bei beispielsweise der FM Synthese einfache Wellen sind (Sägezahn, Square, Triangle) die im Grunde nur in ihrer Frequenz und Lautstärke moduliert werden können, können die Wellenformen bei wavetables an sich schon verändert werden (durch beispielweise Phase, Distortion etc.)
Eine noch sehr einfache, Sinus-artige Welle.Eine bereits stark veränderte Wellenform.
Unter dem “Table” kann man sich mehrere abgespeicherte oder erstellten Wellenformen übereinandergestapelt vorstellen, die alle für sich schwingen. Mit beispielsweise einem LFO und anderen Modulationsquellen kann man dann zwischen diesen Wellenformen wechseln und einzigartige Klänge bauen. perfekt für Pads, Strings und andere langanhaltende Klänge.
Das Prinzip der ”Schichten” sehr vereinfacht.Das Prinzip der ”Schichten” in der kreativen Anwendung.
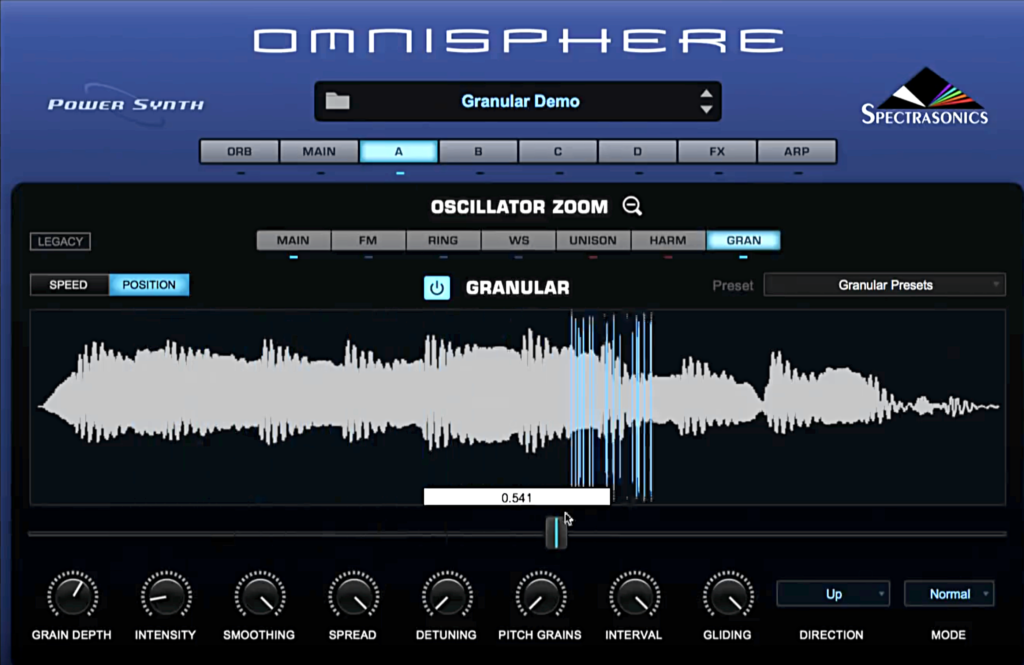
GRANULARE SYNTHESE
Diese Syntheseart basiert auf kleinen, idealerweise 10-50 Millisekunden langen Klangpartikeln eines Sounds, genannt “Grains”. Sie können ihren Ursprung in Samples oder in Synthesizer Signalen haben.
Die “Grains” werden dann so schnell hintereinander abgespielt, dass durch den dabei entstehenden Effekt interessante Klangtexturen entstehen können.
Grains werden dabei meist in ihrer Tonhöhe, Phase, Lautstärke, Hüllkurvenparameter usw. Moduliert, um einen lebendigen, sich verändernden Sound zu bekommen.
Zusätzlich können “Wolken” von anderen Grains, die entweder länger sind oder beispielsweise anders moduliert werden dazustoßen.
Granulare Synthesizer sind bisher ausschließlich in digitaler Form zu erhalten. Plugins wie Outputs “Portal” oder Spectrasonics “Omnishpehre” bedienen sich beispielsweise an der Granular Synthese.
PHYSICAL MODELING
Anstatt von schwingenden Oszillatoren, LFOs und Filtern, erzeugen hier mathematische Modelle einen Klang bzw. eine Klangveränderung. Physical Modeling wird daher besonders oft zur Nachbildung echter Instrumente, wie zum Beispiel Geigensaiten oder Trommeln eingesetzt.
Es können sowohl akustische Eigenschaften des Klangs wie zum Beispiel die Festigkeit des Resonanzkörpers, das Verhalten beim Anschlag oder das Zupfen einer Saite, als auch die akustische Umgebung wie ein Konzertsaal oder ähnliches anhand mathematischer Modelle nachgebildet werden.
“Um beispielsweise einen Drum-Sound zu modellieren, kommt eine Formel zum Einsatz, die den Kontakt eines Schlägels/Drum-Sticks auf dem Fell nachbildet. Hier spielen etwa die Eigenschaften des Fells, (Masse, Dichte, Steifheit etc.) oder das Volumen und die Beschaffenheit des Resonanzkörpers der Trommel eine Rolle.”
Meistens gehen die Einstellmöglichkeiten eines Physical Modeling Synthesizers weit über die des nachgeahmten Instruments in der Wirklichkeit hinaus, so kann man beispielsweise das Fell einer Trommel während der Performance größer oder kleiner werden lassen.
Bevor wir uns einige klassische Synthesizer und deren Sound ansehen ist es wichtig, die verschiedenen Arten der Klangsynthese zu verstehen. Denn selbst wenn die Grundlage aller analogen Synthesizer auf elektronischen Bauteilen besteht, ist jede Form der Synthese unterschiedlich. Generell gesprochen gibt es diese 5 Formen:
Subtraktive Synthese
Additivie Synthese
FM-Synthese
Wavetable-Synthese
Granulare Synthese
Physical Modeling
In diesem Blogeintrag werden die ersten 3 dieser Liste genauer beschrieben und erklärt.
SUBTRAKTIVE SYNTHESE
Bei dieser Art der Klangsynthese startet man mit einer einfachen Oszillatorwelle. (je nach Modell hat man hier einige zu Verfügung). Direkt im Anschluss folgt durch diverse Filter eine Bearbeitung dieser Welle. Absenkungen im Bass-, Mitten-, aber auch Höhenbereich formen hier den Basiston, der anschließend auch noch durch LFOs und Hüllkurven moduliert werden kann (mehr dazu später). Ein guter Vergleich wäre jedenfalls der eines Bildhauers, der mit einem undefinierten Marmorblock startet, und sich seine Gewünschte Skulptur (in unserem Fall der Ton) Schritt für Schritt formt.
Da Diese Form durch besagte Filter und Abschwächungen des Signals zu seinem Klang kommt, einigte man sich darauf sie “subtraktive Synthese” zu nennen.
KORG MS-20 SYNTHESIZER
Bei Synthesizern mit subtraktiver Klangsynthese wird man relativ selten bis nie einen Sinuswellen-Oszillator finden, da die anschließenden Filter bei einer solchen Wellenform nicht “greifen” würden. Sie würden lediglich die Lautstärke der Welle beeinflussen. Daher sind nahezu alle subtraktiven Synthesizer mit obertonreichen Wellen bestückt, wie zum Beispiel Sägezahnwellen oder Rechteckswellen.
Der gängigste und weitverbreiteste Filter Typ, der bei diesen Synthesizern zum Einsatz kommt, ist der Low-pass Filter. Durch die “Cutoff” Frequenz, kann man die höheren Anteile eines Tones mit ihm herausfiltern. Natürlich gibt es aber auch andere Filter, die zwar nicht so oft wie der Low-pass vorkommen, aber dennoch eine Daseinsberechtigung haben. Im Endeffekt läuft es aber immer auf eine Sache raus, die den Sound erst richtig interessant macht: Das Modulieren bestimmter Parameter mittels eines LFOs oder das Formen der ADSR Kurve (Hüllkurve).
Auf diese Parameter und Formungsmöglichkeiten kommen wir aber im Blogeintrag 6 nochmal darauf zurück.
Auf die Frage, was ein analoger Synthesizer sei, wird man des Öfteren die Antwort “einer mit subtraktiver Synthese” zu hören bekommen. Selbstverständlich gibt es diese auch schon als digitale Kopien und Nachbauten in Software-Form. Bei ihnen spricht man von “virtuell-analogen” Synthesizern.
Um ein paar Klassiker zu nennen, die sich diese Snyhteseform zunutze machen:
Minimoog
ARP 2600
MS-20
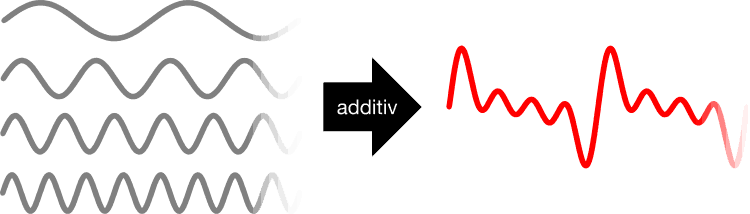
ADDITIVE SYNTHESE
Gegensätzlich zur subtraktiven Synthese, werden hier mehrere Sinuswellen überlagert, welche von Oszillatoren erzeugt werden. Dahinter steckt die Idee, dass man mit dieser Methode nahezu jeden möglichen Ton erzeugen kann – in der Theorie. In der Praxis setzt die Technik hier jedoch immer wieder Grenzen und Hindernisse, welche diese Art von Synthesizer besonders knifflig machen. Jedoch ist es genau das, was “happy little accidents” passieren lässt und dem Synthesizer blühendes Leben einhaucht.
Additive Synthesizer werden oftmals für die Erzeugung Orgel- oder E-Piano ähnlicher Sounds benutzt. Wer den Sound der bekannten “Hammond Orgel” kennt, weiß was gemeint ist.
Im Grunde bieten die meisten additiven Synthesizer Oszillatoren an, mit welchen man einen Ton in seine einzelnen Komponenten aufteilen beziehungsweise zusammenbauen kann (=additiv).
Wer die Fourninsche Analyse kennt weiß, dass ein Ton aus einem Grundton und seinen Obertönen besteht. Bei der additiven Synthese, bildet der am langsamsten schwingende Oszillator diesen Grundton. Alle weiteren Oszillatoren bilden dann die Obertöne. Bei einem Synthesizer mit 4 Oszillatoren würde die 2. Welle doppelt so schnell schwingen wie die erste, die 3. doppelt so schnell wie die zweite, und die 4. doppelt so schnell wie die dritte Welle. Somit würde man einen harmonisch klingenden Ton aufbauen.
Additive Synthese
Technische Schwierigkeiten der additiven Synthese:
Um mit der additiven Synthese einen komplexen Klang zu erzeugen, braucht ein additiver Synthesizer viele Oszillatoren. Jeder davonmüsste idealerweise auch in seiner Tonhöhe und Lautstärke veränderbar sein. Wenn jeder dieser Oszillatoren auch noch mit einer ADSR Hüllkurve ausgestattet wäre, käme man mit 5 Sinuswellen auf eine Anzahl von 30 einzeln ansteuerbaren Parametern. Wären es beispielweise 15 Oszillatoren käme man auf 90.
Wie man anhand dieses Rechenbeispiels erkennen kann, ist die Herausforderung der additiven Synthese die, einen Synthesizer zu bauen, dessen Bedienung trotz etlicher Parameter so einfach und intuitiv wie möglich bleibt.
Da dies – besonders in der analogen Welt – kein einfaches Unterfangen ist, gab es nicht allzu viele additive Synthesizer in der Geschichte. Ein paar wenige bekannte waren jedoch:
Kawai K5
New England Digital Synclavier
Hammond-Orgeln
FM SYNTHESE
m einfachsten Beispiel wird bei der FM Synthese die Frequenz eines Oszillators A durch die Frequenz der Oszillators B moduliert. Die Welle des Oszillators A ist hier die Trägerwelle auch genannt “Carrier”. Osz. B dient hier nur der Modulation und wird “Modulator” genannt.
An dieser Stelle gilt es zu betonen, dass es in der Welt der FM Synthesizer viele unterschiedliche Wege gibt diese Oszillatoren in Relation zu stellen. Diese Ketten, bestehend aus Carrier, Modulator (die einzelnen Bausteine werden – egal ob Carrier oder Modulator – auch “Operator” genannt) nennt man “Algorithmus”.Also nicht die Oszillatoren selbst, sondern die Art und Weise wie diese Operatoren verbunden sind und welcher was moduliert / steuert.
Fm Synthese
Typisch für diese Syntheseart sind glockenartige Timbres, metallisch wirkende Töne und Klänge die an ein E-Piano erinnern. Ebenso möglich und sind fette, knackige Bässe und Bläser-artige Sounds.
Um besagte Klänge zu erzielen, muss die Frequenz des Modulators mindestens 20 Hz betragen. Erst dann spricht man von einer “Audioratenmodulation”. Vibrato wird mit einer Frequenz von bis zu 10 Hz erzeugt.
Bei Synthesizern, die sich der FM Synthese bedienen, findet man oftmals mehrere Oszillatoren/Operatoren. Meist sind es 4-6 Operatoren pro Stimme. Dies und die oftmals durch andere Algorithmen verknüpfbaren Operatoren ermöglichen sehr komplexe Klangformungen und nahezu unendlich Möglichkeiten.
Natürlich gibt es die gegenseitige Modulation zweier Oszillatoren auch in anderen Synthesizern, die nicht FM-Synthese betreiben. Bei ihnen nennt man das dann “cross modulation”.
Der wohl bekannteste Synthesizer der FM- Synthese: der Yamaha DX7
Im Nächsten Blogeintrag: Wavetable und Granularsynthese, Physical Modeling
Kill your darlings. Nachdem die Recherche über Zucker und Konsumverhalten nicht den gewünschten kreativen Workflow erbracht hatte, ist es nun Zeit das Thema zu wechseln und sich auf ein neues zu konzentrieren.
Nun wird die Fotografie als Visuelle Sprache im Grafik Design untersucht. Ziel ist es, die verschiedenen Teilgebiete der Fotografie zu betrachten. Bevor ein Blick auf die Amateur- und Analogfotografie geworfen wird, wird die Visuelle Sprache als solches untersucht. Vielleicht ergeben sich während der Recherche wichtige Rückschlüsse auf das Thema Zucker – denn geplant ist, dass Food Photography und Produktfotografie ebenfalls untersucht werden. Deshalb ist eine Kombination aus diesem Thema und dem bisher recherchierten durchaus möglich.
Als Visuelle Sprache wird eine Form der Kommunikation bezeichnet, die im Gegensatz zur formalen Schriftsprache visuelle Elemente verwendet. Diese Elemente werden gezielt eingesetzt, um eine Idee oder eine Bedeutung visuell zu vermitteln. Beispielsweise können das Linien, Formen, Farben, Texturen und Muster sein, die in bestimmten Skalierungen, Winkel und Proportionen ausgerichtet werden. Die Elemente der visuellen Kommunikation repräsentieren dabei Konzepte im räumlichen Kontext. Sprechen und Lesen basieren auf einem zeitlich linearen Ablauf, wobei die visuelle Kommunikation auch parallel funktioniert. Oftmals werden Infografiken gezielt eingesetzt, da sie mittels Diagrammen, Karten und Symbolen einen bestimmten Inhalt vermitteln und aussagekräftige Beziehungen visualisieren. So können komplexe Daten auf eine prägnante Weise dargestellt werden.
Das Visuelle Denken gehört ebenfalls zur Visuellen Sprache und dient als Grundlage im Entwurfs- und Gestaltungsprozess bei Designern. Skizzen, Scribbles und Zeichnungen dienen als Hilfsmittel und visualisieren den kognitiven Denkprozess. Außerdem vereinfacht das Visuelle Denken Kommunikationsprozesse, in dem eine Idee, die Fragestellung und die möglichen Lösungsansätze visualisiert werden.1 Die angeborene Begabung unterstützt die Fähigkeit, Probleme zu lösen, die Phantasie und die Kreativität. Weiterführend ist die Synästhesie zu nennen, bei der verschiedene Gehirnbereiche auf besondere Art und Weisen miteinander verbunden sind. Dadurch werden bestimmte Wahrnehmungsphänomene und Denkprozesse ermöglicht. Synästhetische Wahrnehmungen zum Beispiel sind farbiges Hören oder konsistente Zuordnen von Farben zu bestimmten Buchstaben oder Zahlen.2
Ein weiterer Teil des Visuellen Denkens umfasst die Semiotik. Auch als Zeichentheorie bekannt, arbeitet die Visuelle Sprache auf einer symbolhaften Ebene mit Elementen und Bilder, bei denen immer der soziale und kulturelle Hintergrund berücksichtigt werden muss.3 Das Gehirn interpretiert das Wahrgenommene und nimmt das empfangene Signal in einer Form von Emotion, Handlung oder Gedanken auf. Die Semiotik ist ein wichtiger Teil der Kommunikationssysteme, denn dadurch kann der zu vermittelnde Inhalt mithilfe der der symbolhaften Ebene aufgenommen und verarbeitet werden.
Die Visuelle Sprache lässt sich also in verschiedenen Teilbereichen gliedern, die alle miteinander verbunden sind. Wie bereits erwähnt, spielen Formen, Farben und Symbole dabei eine wichtige Rolle. Im Design wird stets Inhalt und Information vermittelt, die im Zusammenspiel mit einer Visuellen Sprache eine eigene Inhaltsebene erzeugen. Unterstützt wird diese Inhaltsebene oft mit fotografischen Elementen oder Bildern. Dieser Aspekt wird in den folgenden Blogposts betrachtet, damit verständlich wird, weshalb Fotografie als Teil der Visuellen Sprache gesehen wird.
Quellen:
1 Vgl. Diefenbach, Marc: Workbook Visuelles Denken. Ideen generieren, Kundenskizzen anfertigen, Schibbeln schnell gestalten. BoD – Books on Demand (Hrsg.), 2013, S. 6 2 Vgl. Deutsche Synästhesie Gesellschaft e.V.: Was ist Synästhesie? http://www.synaesthesie.org/de/synaesthesie – Zugriff am 05.01.2022 3 Vgl. Fellbaum, Klaus: Sprachverarbeitung und Sprachübertragung. 2. Auflage, Springer Vieweg, 2012, S. 10
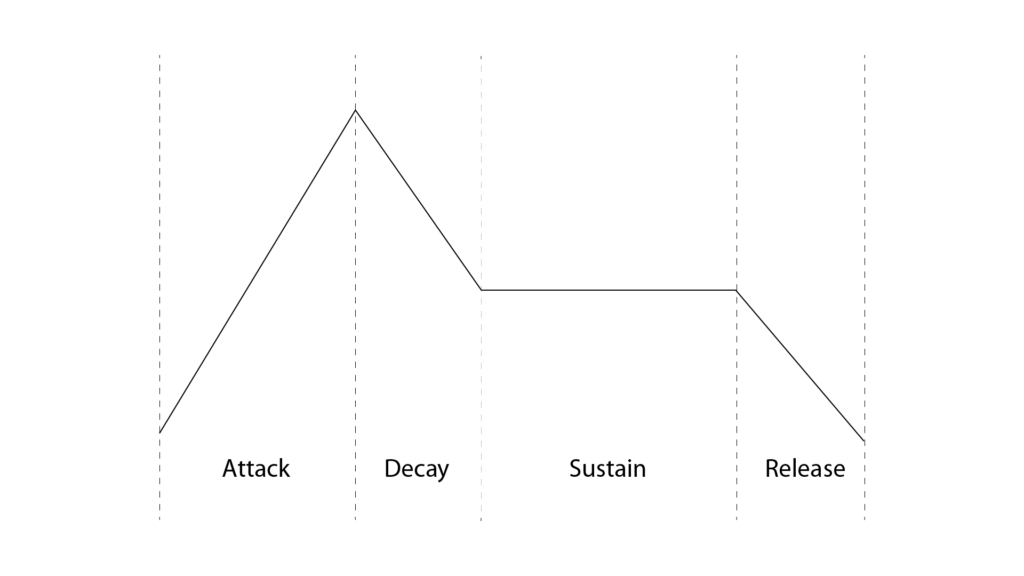
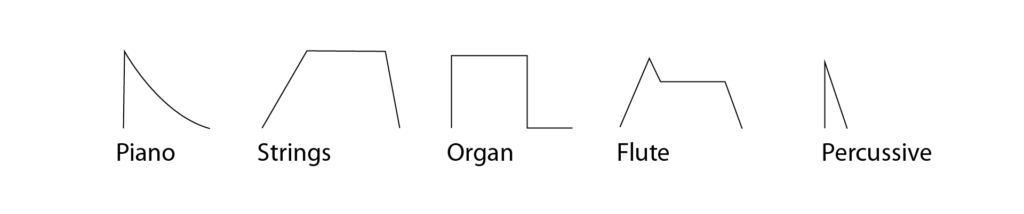
For the Musician–Synthesizer Interface it is important to translate the pitch, Amplitude-envelope and note length. But those are the Basic values that define the most basic values of translating Music into the air. The pitch and the relative length are defined for example by sheet music and the envelope by the Characteristics of the instrument played. The most common envelope found in synthesizers ist the ADSR shape standing for ‚attack‘, duration of the rising ramp of the signal, ‚decay‘, duration of falling ramp of the signal starting after the attack ramp is at its peak value, ‚sustain‘, value of the held signal as long as the gate is open and ‚release‘ duration of the signal falling from the last value to zero after the gate is closed. This is also one of the simplest ways to portray many acoustical instruments in their Amplitude envelopes.
But the timbral structure of sounds are mostly not only described by their amplitude envelopes. Many musical instruments are defined by variations in pitch, and the color of the sound. So the simple amplitude picked-up by an envelope follower is a very basic tool to define the sound of a musician. Furthermore it only draws conclusions of the basic values a musician puts into his instrument. So to capture a musician more fully her expression plays a big role in the interpretation of control voltages.
So how can we define musical expression? As said before in most notation of western music pitch and relative length are written down, things like tempo and dynamics or direction for technique are written down in words or abbreviations. But the finer points of a performance which are mostly inherent to every musicians individuality are much nowhere to be found except the playing of the musician. So the common expression for tempo in italian are widely known as follows roughly from slow to fast: adagissimo, adagio, lento, andante, andantino, allegretto, allegro, presto, prestissimo. (Britanica)
As for dynamics roughly from quiet to loud: piano, pianissimo, mezzo piano, forte, mezzo forte, fortissimo and some changes in dynamics: fortepiano (loud then soft) sforzando (sudden accent) crescendo (gradually louder), diminuendo (gradually softer).
So those are nowadays all the definitions which a composer uses to translate his musical thoughts to the performer. but it wasn’t always like this.
„…[I]n much 17th- and 18th-century music, the composer notated only the main structural notes of the solo part, leaving the performer to improvise ornamental figuration.“
https://www.britannica.com/art/musical-expression
Those figurations or ornamentations gave the musician the freedom to express themselves and influence the tradition of the then current music.
Excerp from a Sonate by Arcangelo Correlli Da Fusignano Opera Quinta
Here you can see the bottom two lines are the composers’ structure of the piece and the top line are the individual ornaments an artist put over the piece.
In modern Midi keyboards, there are several possibilities to record expressions. The widest spread feature is the velocity control. This parameter is controlled by the velocity one hits the keys and thus can be easily added by keyboard performers in their playing like they would playing an acoustic instrument. With the synthesizer and the possibility to create the sound of the instrument individual to the performance also came the possibility to control parameters of a sound which in acoustic or electro-acoustic keyboard instruments with keys and pedals only really possible. The Pitch and Mod wheel were introduced to make such changes possible. The first was a spring-actuated week or stick which was mostly used to modulate the pitch like with a guitar. The other was an adjustable heel with which one could send fixed values or modulate them manually. The fourth modulation source developed for keyboard synthesizers is aftertouch. As the name suggests, it is applied by altering the pressure after the key is depressed. This can be applied mono- or polyphonically. All of those controls added to the expressivity of synthesizer performances mostly. Only one of those controls is determined before the tone or as the tone is generated. The others are applied in the decay of the sound. So those are 4 control values that have been proven to add expressivity in performance.
Ofcourse, these weren’t the only tools that were developed to do very expressive performances, although they are the most common ones. There is a multitude of midi controllers to add expression to an electronic music performance. The expressive E ‘Touché’ or ‘Osmose’, Buchla and Serge capacitive keyboards and joystick-controllers on synths like the EMS Synthy, Korg devices like the Sigma or the Delta and as controller module for Eurorack-, 5U-, Buchla- and Serge-modules.
Other Concepts
Then there are control surfaces that take another approach to the whole concept of the Keyboard entirely. These Concepts go often but not always hand in hand with a synthesizer engine.
HAKEN Continuum
The Haken Continuum for instance is a Synthesizer with a control surface that can detect movement in 3 axes.
The Haken Continuum Fingerboard is an instrument born to be as expressive and as rewarding to play as an acoustic instrument. The uniquely designed sensitive playing surface has been symbiotically merged with its powerful synthesis sound engine to produce a truly unique playing experience. The Continuum is a holistic electronic instrument that puts its player at the heart of a uniquely fluent, gestural and intuitive musical playing experience.
The Roli SEA Technology which is implemented in rolis seaboard controllers is as roli puts it:
“Sensory, Elastic and Adaptive. Highly precise, information-rich, and pressure-sensitive. It enables seamless transitions between discrete and continuous input, and captures three-dimensional gestures while simultaneously providing the user with tactile feedback.”
www.roli.com
Roli Seaboard Rise 49
Linnstrument
The Linnstrument is a control surface developed by famous instrument designer Roger Linn. Interesting here is the approach to not apply a piano-style keyboard but rather use a grid-style keyboard which rather reminds of the tonal layout of string and guitar instruments. With the linnstrument there is also a release velocity recorded which places it even more into guitar territories where pull-offs, when one rapidly pulls of the finger of a string to excite it and thus making it sound, is a standard technique.
So few of the looked at control surfaces if any have more than 4 modulatable values. This would be then a minimum for a module that should be able to translate the expression of an instrumentalist into control voltages.
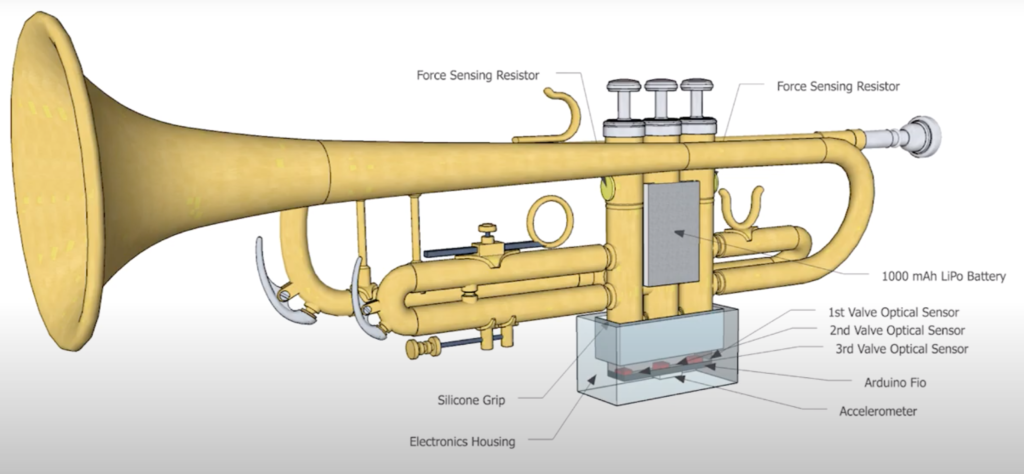
Sarah Belle Reid is a Trumpet player and Synthesist who takes the sound of her brass instruments and puts them through her modules Systems like Buchla, Serge, or Eurorack. She has developed a device with which she translates her trumpet playing to CV and/or MIDI messages called MIGSI.
They Developed MIGSI in a big part to enable her to use all of the techniques Sarah Belle Reid has developed on her Instrument to translate into more than ‘just’ her instrument and open the horizon of the instrument the electronic music-making possibilities.
MIGSI
MIGSI: Minimal invasive gesture sensing interface. She calls it ‘electronically augmented trumpet’ too. The device was co-developed by her and Ryan Gaston around 2014. They also founded ‘Gradient’ a joint venture between them where they develop “handmade sound objects that combine elements of the natural world with electronic augmentation.” (vgl.: Gradientinstruments.com).
Migsi is a Sensor-based Interface with 3 types of sensors and 8 streams of Data. Pressure sensors around the valves which read the pressure of the grip force, an accelerometer that senses movement of the Trumpet, and optical sensors which reads the movement of the Valves.
The hardware is then read by a MIGSI app which is a MAX map Patch. The app is used to process thee the audio signal of the trumpet, modulate external equipment with the sensor input or modulate a synth engine inside the MIGSI App.
While presenting my Ideas and reasoning how and why I choose the order of interest in them, I could give a clear statement of intention that programming and electronics should be a vital part of the final product.
Supervision
From the Faculty of KUG Prof. Marco Ciciliani has chosen to work with me on my project. The Projekt – ‘Kidnapping the Sound of an Instrumentalist’ was my least favorite, but only because I would have done it outside of Uni anyway. His reasoning for choosing me was that he works with modular synthesis too.
Project
‘Kidnapping the Sound of an Instrumentalist’
The main focus should be that the forthcoming device should be very performable. This means that I have to find a working surface which for one is familiar to me and secondly gives me enough room to develop in multiple directions. The performance aspect means that the Instrumentalist has to be able to convey their expression to the device and I have to be able to pick it up and use it for further modulation of my setup. Below is a chain of thoughts which stood at the very beginning of the project which concludes in a module for a modular Synthesizer.
The Idea of developing a Musician Interface Module was well received by Prof. Ciciliani with the remark that for the technical side I have to be self-sufficient for the largest part.
1st Thoughts
EXPRESSION OF A MUSICIAN LIES VERY MUCH IN THE SONIC COLORATION OF THE SOUND – FFT ANALYSIS
COULD WELL BE THE TOOL TO EXTRACT PARAMETERS FOR THE SONIC COLOR OF A SOUND – BREATH
CONTROLLERS RECORD EXPRESSION PARAMETERS TOO – COULD GRANULAR SYNTHESIS BE A GOOD WAY TO
CAPTURE SONIC COLOR OF A SOUND – IS GRANULAR SYNTHESIS ONLY A EFFECT OR DOES IT MAKE THE
SOUND ITS OWN – HOW MANY PARAMETERS DOES EXPRESSION HAVE – IS THERE EVEN A NUMBER – ARE
THERE DIFFERENCES BETWEEN INSTRUMENTS – ARE THERE ANY SIMILARITIES –
A MODULE: THE MUSICIAN INTERFACE
Input
For the Analysis of the instrument, Music Information Retrieval (MIR) was suggested. Music information retrieval (MIR) is the interdisciplinary science of retrieving information from music. MIR is a small but growing field of research with many real-world applications. Those involved in MIR may have a background in musicology, psychoacoustics, psychology, academic music study, signal processing, informatics, machine learning, optical music recognition, computational intelligence, or some combination of these.
Machine analysis and human hearing often correlate unexpectedly. High frequencies for example have a lower audible harmonic spectrum than Lower frequencies but are received vastly differently by the human ear in terms of expression or sonic coloration. So there are many Experiments to attempt to find the right algorithm and workflow to translate expression by the musician.
MIR is inherently digital so the module will probably be driven by some kind of DSP. So the question is if there is a programable DSP chip with the right periphery to build a module around? Like a DSP raspberry Pi. Bela board, Arduino, Daisy, Teensy,…
To choose a topic for our semester project work we should develop 3 ideas. One of these Ideas could form our master theses in the 4th semester. But one of the ideas should ideally be a topic for the next 3 semesters.
My emphasis in collecting my thoughts for these ideas was to support my interest in topics I wanted to learn in the next two years. My primary interest of mine is sound synthesis and composition. With the second point, my approach has always been performance-based. Therefore developing an instrument of some sort was a logical decision.
Experts conducted a Usability Review following a user test on three potential users corresponding to the target. The usability review considers the responses from users on how they feel, perceive, and achieve their goals on tasks. The usability review takes account of the different factors to establish an analysis: 7 usability attributes, 10 Heuristics, 20 UX laws, and the expert’s experience.
Before analysis results:
In this user test, the three users have to perform these specific tasks:
Share meeting details to invite a person who’s not a part of the current meeting
Add a person named “Austin Brandon” to the call
Take some notes during the meeting which would be 50 characters long.
Share a particular screen along with the computer audio.
Stop sharing your screen after you’ve shared your screen.
Send a personal message to one of the participants of the video call.
The aim will be to obtain an analysis using the Seven usability attributes:
Effectiveness: Can the user accomplish specific tasks through this system? (ISO 9241-11)
Efficiency: How does the product help the user to perform tasks with the least amount of resources? (ISO 9241-11)
Safety: How does the system avoid undesirable situations so that the user feels safe?
Utility: Does the product provide the right functionality to accomplish tasks easily?
Learnability: Can the user learn the system as quickly as possible and without too much effort?
Memorability: How easily can the user remember how to use a product?
Satisfaction: Is the individual satisfied by using this product? (ISO 9241-11)
Analysis of the results:
Effectiveness: The user can perform the most basic tasks during the meetings. But we can notice that the user can make several mistakes by clicking on the wrong options, resulting in breaking some UX laws.
Efficiency: Users can complete tasks in no more than 15 to 20 seconds. But at some points, some tasks are not easy to perform for those who have not used the platform not often, so teams made some changes to the interface, but this did not make it easy for experienced users to get used to.
Safety: The user makes many errors while navigating the system, most of which are due to language design discrepancies, high latency during interactions with the system, as well as some transgressions of UX laws (Fitt’s Law, Jacob’s Law, Miller’s Law)
Utility: The necessary tasks are feasible, but the problems lie in the time and effort to do them.
Learnability: It is sometimes difficult for a novice user to get to grips with the system, which differs from other virtual discussion software. But the various possibilities are more than enough for the user to learn, so he can learn the most basic uses with some latency, due to additional features that add layers of complexity.
Memorability: Once learned the system, it is difficult to forget the navigating process of the system and not make the same mistakes again. The system has a uniform language design that allows for a better mental representation of the system and easy navigation. The system has tips to make it easier to navigate. Error messages are clearer, and automatic suggestions allow us to overcome them.
Satisfaction: The tool at hand is an alternative means for professionals and academics in that it can satisfy the continuity of work through video-conferencing, instant chats, and file exchange. But some learnability and safety details need to be fine-tuned to improve the satisfaction of the user, so to guarantee this satisfaction, the user has to build a mental model of this system to improve the ease of use.
Conclusion
As a whole, MS teams meet the essential needs of the user. Let’s remember that students and professionals had to be equipped with technological means to pursue their activities. The software developed by Microsoft answers the call by proposing functionalities satisfying major active users. Before taking this satisfaction into account, the idea of using this software came in spite due to the pandemic, the majority of novice users were apprehensive about this new system which was unusual compared to other videoconferencing software. This apprehension is mainly due to the vast possibilities in terms of content and functionalities that push the novice user to a necessary learning curve. We have noticed in this analysis that the user can learn the basic functionalities of the software and thus have a mental model of the system. However, we notice errors mainly due to a high latency during interactions and a transgression of the UX laws, which nevertheless allowed Microsoft to make some modifications. Finally, the learning curve will always lie in the time and effort required to remember the system.
However, the software has advanced features that are still not explored yet which are necessary among the basic features we presented previously. For example, the automatic access to other software for productivity or other purposes.
After having dissected the analysis of this software in more detail. I would like to set up a survey at the institute of design and communication to get an overall impression of the software and carry out some user testing with experienced and novice users and compare the results.
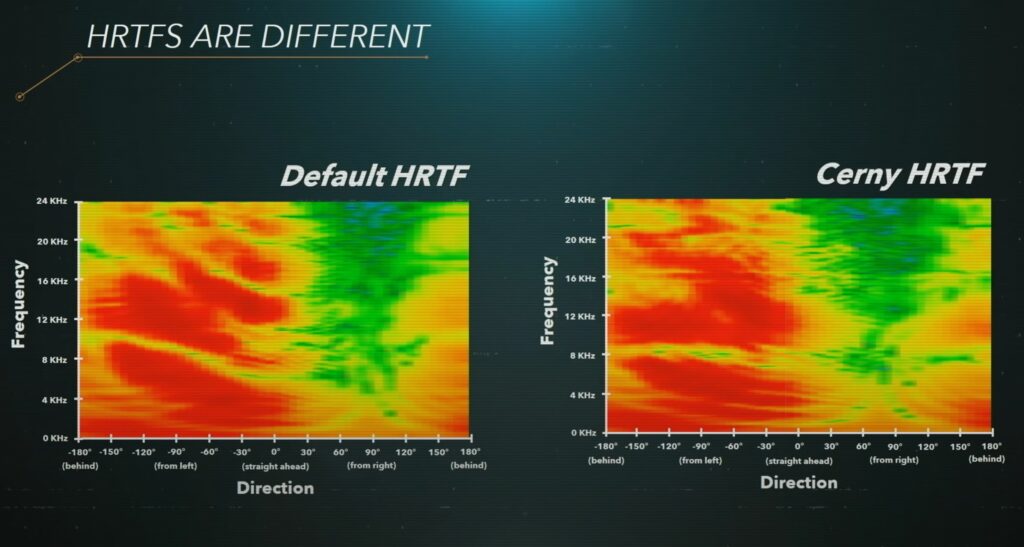
_Back in early 2020, Mark Cerny, the lead system architect for the SONY PlayStation Company held a talk about the soon to be released PlayStation 5 console an its technological aspects and achievements. He explained how they ventured into the field of a new audio technique, the 3D audio engine TEMPEST – it makes it possible for users, to hear ingame sounds with a feeling, as if they were happening around them, by some clever tricks outsmarting our brain and the way it detects sounds. This is, shortly speaking, by measuring the time between an incoming sound signal on the one ear and the arrival on the other ear, defined by the inner distance of our ears to each other, which the brain knows inherently. So, timing sounds just with the right time between left and right headphone speakers the illusion of the sound happening in real life can be achieved.
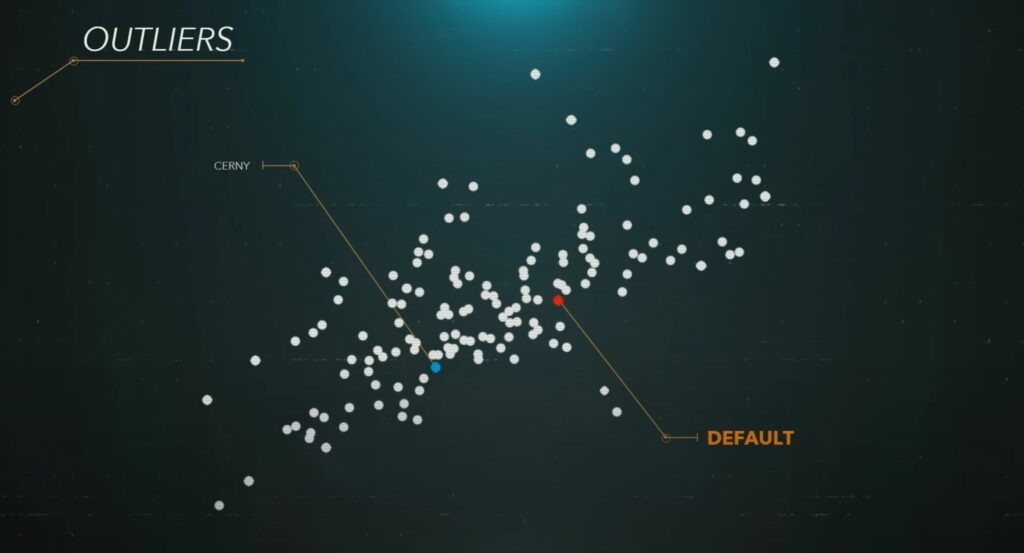
_To get this done, they scanned several hundred peoples hearing data, there known as HRTF (Head Related Transfer Function) and handpicked some of the most common ones to put it into the TEMPEST engine. He also explains that given the fact if this complex and very subjectional/individual perception – and the fact not every user can be scanned to get their personal HRTF – maybe not everyone is physically able to perceive 3D audio correctly – for some it only seems like a bit better stereo audio.
So, in the end one could say future technologies can open the doors for some, but slam the doors shut for others. Although they will try to synthesize HRTF data in the future to maybe make it able to even a wider range of people it may be locked aways for some forever.
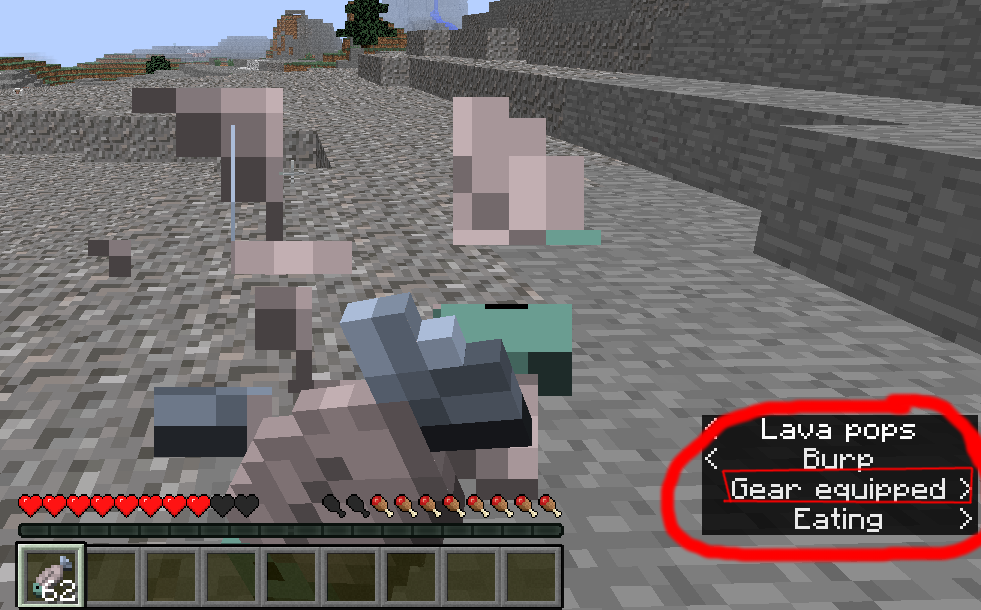
_On a side note, MINECRAFT (MOJANG) also did some development into a highly sophisticated system for full 3D spatialization for ingame sounds as an optional feature, meaning you could determine the location of a noise emitter very accurately by hearing it alone. In the end, this system was turned down serval notches (pun intended) to it only determining, if a sound offscreen comes more from either the right or left side and indicated this with an arrow appended to the subtitles pointing in either one of these to directions. They scrapped the idea of spatial sound effects because they realized in competitive games this feature could, if turned on, help players gain an unfair advantage against other which chose not to play with it.

















{kind=link}